
Stress-Testing Large Language Models’ Analogical Reasoning Abilities

Hello all. This post is about some very recent research results on LLMs and analogy, and a discussion of a debate that has arisen about them. Warning: I get a bit into the weeds here.
If you’re already familiar with the letter-string analogy domain, you might want to skip to section 2.
(1) Hofstadter’s Letter-String Analogy Domain
Way back in the 1980s, Douglas Hofstadter proposed the challenge of modeling human analogy-making using a “microworld” of letter-string analogy problems.1 Here are some examples:
If the string abc changes to the string abcd, what is the analogous change to the string pqrs?
If the string abcde changes to the string abcdf what is the analogous change to the string ijkl?
If the string rstuv changes to the string vutsr what is the analogous change to the string efghij?
If the string mnovq changes to the string mnopq what is the analogous change to the string wxmz?
Hofstadter wasn’t interested in letter strings, per se, but in analogies more generally. In the letter-string domain, each string was meant to represent a mini-“situation,” in which different objects (letters or groups of letters) played particular roles. Hofstadter saw the perception and mapping of roles as the crux of any analogy:
“What does one take literally, what does one see as playing a role…? What kinds of familiar structures is one willing to see as identical to each other? When is it necessary to start inventing new ways of perceiving a given situation in order to fit it into pre-existent frameworks, which then allow already-familiar roles to emerge? What remains firm, and what slips? …[These] are the chief concerns of the analogy-maker…these issues are the heart and sole of the Copycat project.”2
The Copycat project was to create a computer model of human analogy, using letter-string analogies as “stand-ins” for general analogy-making. As Hofstadter wrote, “[W]hat I sought to do in Copycat…[was] to lay bare what I saw as the central problems of analogy without any extra clutter of real-world knowledge.” The creation of this model was my PhD dissertation, and I have written about it elsewhere.
It’s important to note that a given letter-string analogy problem doesn’t have a single “correct” answer. For example, for the first problem listed above, you likely answered pqrst (“extend the sequence by one letter”) but many other answers are possible: e.g., pqrsd (“add d to the string”), pqrs (“make the sequence four letters long), abcd (“change the string to abcd”) and so on. Most people prefer the first answer—our real-life sense for the kind of abstraction that makes for a good analogy carries over to this idealized domain. The Copycat program had stochastic elements that enabled it to give a range of answers, and it was able to judge how good an analogy each one was. It typically agreed with human judgement.
(2) GPT-3 and Analogy
Fast forward to 2023. A group of cognitive psychologists at UCLA—Taylor Webb, Keith Holyoak, and Hongjing Lu— used problems from the letter-string analogy domain (along with three other domains) to test GPT-3’s abilities to make analogies. As I mentioned above, there is no single correct answer to a given problem, but Webb et al. used their intuitions to assign a single “correct” answer were to each problem. Using this definition of correctness, they found that GPT-3 was more accurate (had more correct answers) than the average of a group of UCLA undergraduates the researchers tested.3
To “stress-test” this result, my collaborator Martha Lewis and I used the counterfactual task paradigm (discussed in my previous post) to test GPT-3 and later GPT models on some of Webb et al.’s analogy problems.
In our paper we focused on the simplest problems (exemplified by the problems I listed above), what Webb et al. called the “zero-generalization” cases.4 All the results I will give are on these cases.
(3) A Replication
First, we replicated Webb et al.’s study comparing humans with GPT-3. While their human participants were UCLA undergrads, we used participants from the Prolific Academic platform, on which people can earn money by participating in academic experiments.

The left plot above shows Webb et al.’s results comparing GPT-3’s average accuracy to that of humans. You can see that the average accuracy of humans was worse than that of GPT-3. Based on this, along with results from other analogy domains, the authors concluded that “GPT-3 appears to display an emergent ability to reason by analogy, matching or surpassing human performance across a wide range of text-based problem types.”
However, our study replicating theirs yielded different results (right plot above): on average, on the zero-generalization problems, humans outperformed GPT-3 as well as more recent versions, GPT-3.5 and GPT-4. We don’t know what accounts for the difference from Webb et al.’s results—it’s possibly due to our different population of human participants, who might have been more incentivized to perform well on the experiment. (It’s also unclear what caused the small difference in GPT-3’s performance between our study and that of the original authors.)
It’s still notable that the GPT models get many of these analogies correct (according to the notion of correctness I described above). However, how robust are these analogical capabilities? One way to test this is using the counterfactual tasks paradigm.
(4) “Counterfactual” Analogy Tasks
The counterfactual task paradigm compares a system on reasoning tasks that include content likely similar to that in the system’s training data (e.g., the English alphabet) with tasks requiring the same reasoning abilities, but on content not likely to be in the training data.
Martha Lewis and I designed two types of counterfactual letter-string analogy tasks. The first was to present a “fictional alphabet” in which some letters are permuted, and ask people and GPT models to solve problems with this fictional alphabet. For example, here is one of the problems, using an alphabet with e and m swapped. Note that, to match Webb et al.’s experiments, the strings are enclosed between square brackets.
Use this fictional alphabet: a b c d m f g h i j k l e n o p q r s t u v w x y z
Note that the alphabet may be in an unfamiliar order.
Let’s try to complete the pattern:
[ b c d m ] [ b c d f ]
[ p q r s ] [
The intended answer is [ p q r t ]. Is that what you got?
The second type of counterfactual tasks used alphabets of non-letter symbols. Here’s an example:
Use this fictional alphabet: & > $ ! + ) < @ = *
Note that the alphabet may be in an unfamiliar order.
Let’s try to complete the pattern:
[ < @ = * ] [ ) @ = * ]
[ $ ! + ) ] [
The intended answer is [ > ! + ) ]
We hypothesized that if a person (or machine) has a capacity for general reasoning about concepts such as “Successorship,” “Predecessorship,” and the other transformation types, they will be able to easily adapt their reasoning to these types of counterfactual tasks.
We tested humans, again using the Prolific Academic platform, on many problems similar to the ones above. We also tested three LLMs: GPT-3, GPT-3.5, and GPT-4. Before presenting the problems, we made sure that the LLMs “understood” the fictional alphabet, meaning that they could say what the “next letter” and “previous letter” was of each letter in the given fictional alphabet—the LLMs generally did very well on this.
(5) Results on Counterfactual Tasks
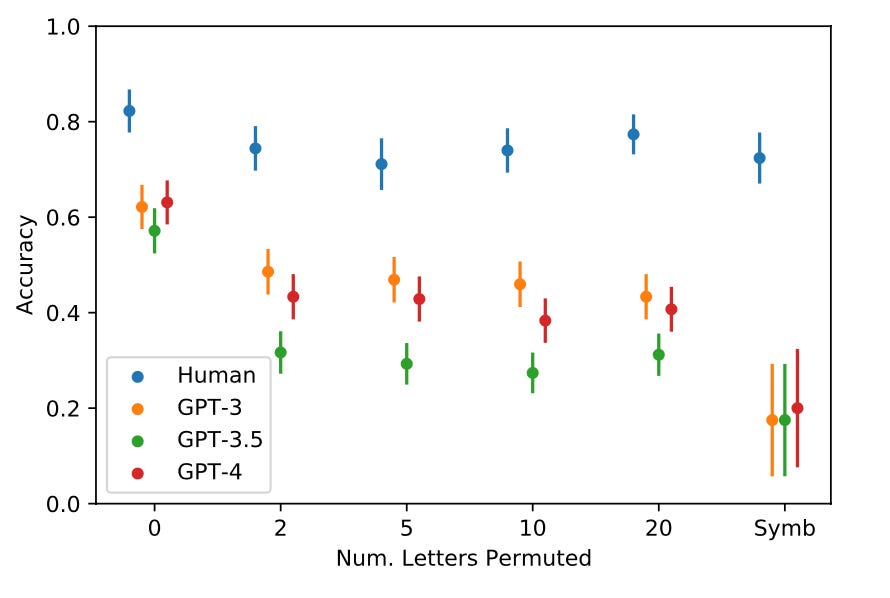
When tested on our counterfactual tasks, the accuracy of humans stays relatively high, while the accuracy of the LLMs drops substantially. The plot above shows the average accuracy of humans (blue dots, with error bars) and the accuracies of the LLMs, on problems using alphabets with different numbers of permuted letters, and on symbol alphabets (“Symb”). While LLMs do relatively well on problems with the alphabet seen in their training data, their abilities decrease dramatically on problems that use a new “fictional” alphabet. Humans, however, are able to adapt their concepts to these novel situations. Another research study, by University of Washington’s Damian Hodel and Jevin West, found similar results.
Our paper concluded with this: “These results imply that GPT models are still lacking the kind of abstract reasoning needed for human-like fluid intelligence.”
(6) Webb et al.’s Response
Webb et al. did not agree with our assessment. They recently published a response to our paper and to Hodel & West’s paper, claiming that the GPT models can indeed perform robust analogical reasoning, but that these models weren’t able to solve the permuted-alphabet problems because “such problems require that letters be converted into the corresponding indices in the permuted alphabet, a process that depends on the ability to precisely count the items in a list.” In other words, the process they believe is required to solve the permuted alphabet problem shown above is to assign each letter in the problem its index in the alphabet. For example,
Given alphabet a b c d m f g h i j k l e n o p q r s t u v w x y z
m is the 5th letter (given the fictional alphabet), f is the 6th letter, p is the 16th letter, and so on.
Webb et al. then tested a more recent version of GPT-4, one that has the capability to generate code to help it solve problems. Given a problem with a counterfactual alphabet, GPT-4 generated code to translate each letter to its index in the alphabet, and used the indices and their numerical differences to solve the problem. This version performed above the level of humans on several types of letter-string analogy problems.
(7) I’m Not Convinced
I disagree that the letter-string problems with permuted alphabets “require that letters be converted into the corresponding indices.” I don’t believe that’s how humans solve them—you don’t have to figure out that, say, m is the 5th letter and p is the 16th letter to solve the problem I gave as an example above. You just have to understand general abstract concepts such as successorship and predecessorship, and what these means in the context of the permuted alphabet. Indeed, this was the point of the counterfactual tasks—to test this general abstract understanding.
Moreover, this notion of counting violates the spirit of the letter-string domain. As I described above, the whole point of the letter-string domain was to get at general mechanisms of analogical reasoning, rather than requiring very domain-specific reasoning—such as counting up the positions of letters in the alphabet, or subtracting the indices of one letter from another. As Hofstadter and I wrote in 1995: “[P]roblems should not depend on arithmetical facts about letters, such as the fact that t comes exactly eleven letters after i, or that m and n flank the midpoint of the alphabet…arithmetical operations such as addition and multiplication play no role in the Copycat domain.”
(8) Conclusion
In this post, I gave a example from my own research of replicating experiments of another group and of using counterfactual tasks to stress-test claims of reasoning in large language models. I also argued that it’s not appropriate to focus on “counting abilities” as what’s missing from these models.
My collaborators and I are in the process of doing similar stress-testing of LLM capabilities on other analogy domains. I hope I’ve communicated the importance of doing such experiments, as well as of scientific replication studies. And, of course, of healthy scientific debates!
D. Hofstadter, Metamagical Themas, Chapter 24. Basic Books, 1985.
Ibid, pp. 563-566.
In an earlier post, I responded to Webb et al.’s paper and the lead author, Taylor Webb, responded to my response.
The “non-zero generalizations” included strings with repeated letters, with numbers or words instead of letters, and other extensions.
A couple of preliminary thoughts, for what they’re worth.
Hofstadter’s string completion examples constitute a very rarified case of reasoning by analogy, with the task reduced to completion of a syntactic or iconographic pattern as per a functionally defined mapping between patterns. In some sense, that was the point, but this compels the question of how much even locally scalable performance on such bare-essence examples is really telling us. As deployed in vivo, as opposed to in vitro, metaphors and analogies are not arbitrary inventions of the moment. They usually serve the purpose of furthering learning and understanding on the basis of historical convention and use preceden (for example, if one knows the account of the Trojan Horse, one can, on being told that the firewall of a LAN is analogous to the walls of Troy in a Trojan horse malicious code exploit, infer that the aim of the exploit is to transition malware through the firewall inside of an innocuous wrapper). One wonders if the ability of LLM to learn by way of this kind of metaphorical induction could be tested. Here, I think we run up against a very fundamental problem, at least in the case of the GPTs. As regards the example, consider that the concept of a ‘trojan horse’ computer virus or malicious exploit is very likely to be at least as well represented in the original training data as the Greek myth. The only way to be 100% sure that what appeared to be learning really was learning and not reliance on innate knowledge would be to test with a model whose original training set had been ablated of descriptions of the exploit type. Given that fine-grained experimental control over pretraining is out of scope thanks to OpenAIs reluctance to allow outsiders access or insight into this phase of the process, even very extensive performance testing of generalization and sample efficiency would seem to have only-slightly-better-than-anecdotal value. Is apparently novel output being synthetically induced, or was it in the knowledge base already? The failure to replicate Webb’s original result may not be irrelevant, here: as long as the GPTs are moving targets and their pretraining and infrastructure remain opaque, doing bona-fide science with reproducible results is likely to prove frustrating.
The fact that the latest versions of GPT can deploy indexical code in support of problem solving is in fact quite impressive; and, modulo your point that humans seem to rely on a much vaguer sense of ‘successorship’, in fact, the possibility that our cortices include the equivalent of neural network transformers for doing some sort of scratchpad list processing is not a hypothesis I’d be prepared to exclude out of hand. However, I have a couple of questions. First, did the LLM deploy the code spontaneously (‘zero-shot’, as it were), or did it have to be explicitly told, via some form of prompt engineering or fine tuning, that this had to be done to solve the problem? And in that case, how explicit did the instruction need to be, and how many example cases did it use? Second, did any of the permuted alphabet testing extend to cases involving principles of idempotence and composition? For example, consider the question ‘A B C D is to A B C __ as what is to ZYXW VUTS RQPO ___?’ (I would take the answer to be ‘NMLK’). To be sure, it’s to be expected that human analogical invention would also be outstripped at some point, but it might be interesting to determine whether LLM performance degrades along the same curve, as opposed to being better or worse. One has the sense that the contextualized evaluation of prior output is the locus of persistent problems for the current generation of neural network transformer architectures, and that the expressivity of requisite formalisms may have something to do with this.
I find this very interesting. I've done a fair amount of informal work on ChatGPT's ability to deal with analogical reasoning. Here's a long post presenting my most recent thinking on that work: Intelligence, A.I. and analogy: Jaws & Girard, kumquats & MiGs, double-entry bookkeeping & supply and demand, https://new-savanna.blogspot.com/2024/05/intelligence-ai-and-analogy-jaws-girard.html
The first part of the post deals with ChatGPT's ability to interpret a film (Jaws). That requires setting up an analogy between events in the film and stylized situations as characterized by some interpretive framework. ChatGPT has some capacity to this. I've tested it on other examples as well. The third and last section concerns the history of economics. Following remarks by an economist, Tyler Cowen, I hypothesized the perhaps economists we first able to conceptualize the phenomenon of supply and demand by analogizing it to double-entry book-keeping. I asked ChatGPT to explicate that analogy, which it did quite well. Of course, it is one thing to explicate an analogy you've been given, and something else to come up with a (useful) analogy in the first place.
In between those two discussions I explain what happened with I asked ChatGPT to explain the following analogies:
A kitten and a bicycle.
A bicycle and a food blender.
A kitten and a clock.
A Jack-in-the-box and the moon.
A clock and a sea anemone.
A garbage heap and a submarine.
A submarine and a gourmet Chinese banquet.
A helicopter and a Beethoven piano sonata.
A novel by Tolstoy and a MiG fighter jet.
A three-dimensional matrix and the Christian Trinity.
I came up with a "coherent" account of every one, despite the fact that they're nonsensical. How do we distinguish between a reasonable analogy and a nonsensical one?