
Evaluating Large Language Models Using “Counterfactual Tasks”

“[O]ne thing is clear: LLMs are not human. But they are superhuman in their ability to extract information from the world’s database of text. Some aspects of their behavior appear to be intelligent, but if it’s not human intelligence, what is the nature of their intelligence?” — Terrence Sejnowski, Large Language Models and the Reverse Turing Test
What Is the Nature of LLMs’ Intelligence?
In previous writings I talked about the difficulties in evaluating the capabilities of large language models. These models have excelled on many benchmarks, but we typically don’t know the extent to which the test items in a benchmark—or sufficiently similar items—appeared in the training data. Are these models understanding and reasoning in a general way, or are they doing what AI researcher Subbarao Kambhampati calls “approximate retrieval” — relying on patterns of text that are contained in the model’s training data?
The Counterfactual Task Paradigm
The counterfactual task paradigm can help answer this question. In this paradigm, models are evaluated on pairs of tasks that require the same types of abstraction and reasoning, but for each pair, the content of the first task is likely to be similar to training data, whereas the content of the second task (a “counterfactual task”) is designed to be unlikely to be similar to training data.
For example, the paper “Reasoning or Reciting: Exploring the Capabilities and Limitations of Language Models Through Counterfactual Tasks” looked at GPT-4’s performance on (among many other tasks) judging whether a set of four opening chess moves is legal. GPT-4 seems to have a good understanding of chess; when it was given prompts such as the following, it was able to answer “yes” or “no” with nearly 90% accuracy:
You are a chess player. Given an opening, determine whether the opening is legal. The opening doesn’t need to be a good opening. Answer "yes" if all moves are legal. Answer "no" if the opening violates any rules of chess. Is the new opening "1. e4 e6 2. Be2 Bc5" legal? Let’s think step by step.
The authors’ counterfactual version of this task was to ask GPT-4 to imagine a new variant of chess where everything is the same except that knights and bishops swap initial positions. Here’s an example prompt for this task:
You are a chess player. You are playing a chess variant where the starting positions for knights and bishops are swapped. For each color, the knights are at placed that where bishops used to be and the bishops are now placed at where knights used to be. Given an opening, determine whether the opening is legal. The opening doesn’t need to be a good opening. Answer "yes" if all moves are legal. Answer "no" if the opening violates any rules of chess. Under the custom variant, is the new opening "1. e4 e6 2. Nfe2 Nc5" legal? Let’s think step by step.
Examples of this version of chess are much less likely to be in the GPT-4’s training data. The authors’ (and my own) intuition is that humans who understand chess could easily adapt their knowledge to this new version. However, GPT-4’s accuracy on this counterfactual task dropped to about 54% (random guessing would yield 50%).
The authors show several other kinds of tasks with similar effects. They conclude that the apparent reasoning abilities of LLMs might rely substantially on patterns in the training data, that is, “approximate retrieval” rather than general abstract reasoning abilities.
Meta’s Yann LeCun voiced agreement on X:

ASU’s Subbarao Kambhampati concurs:

Another paper that used this evaluation paradigm is “Embers of Autoregression: Understanding Large Language Models Through the Problem They are Trained to Solve”. The phrase “Embers of Autoregression” is a humorous play on the title of another well-known LLM paper, “Sparks of AGI”. The idea is that since LLMs like GPT-4 are trained autoregressively (i.e., predicting the next token in the input), their behavior will reflect the biases that autoregression entails.
For example, consider the simple task of reversing the order of words in a sentence:
Input: paintings. the with pleased totally not was he True,
Correct Output: True, he was not totally pleased with the paintings.
You might think that the ability to perform this task wouldn’t depend on the specific words in the sentence. However, while both GPT-3.5 and GPT-4 performed well on this task when the output sentence was likely (that is, the LLMs’ computed probability of each token given the previous tokens was high), these systems were much worse at the task when the output sentence was unlikely, e.g., for this example:
Input: paintings. the with pleased he totally was not True,
Correct Output: True, not was totally he pleased with the paintings.
Here’s what the overall performance looked like, plotted against the LLMs’ computed probability of the output sentence:
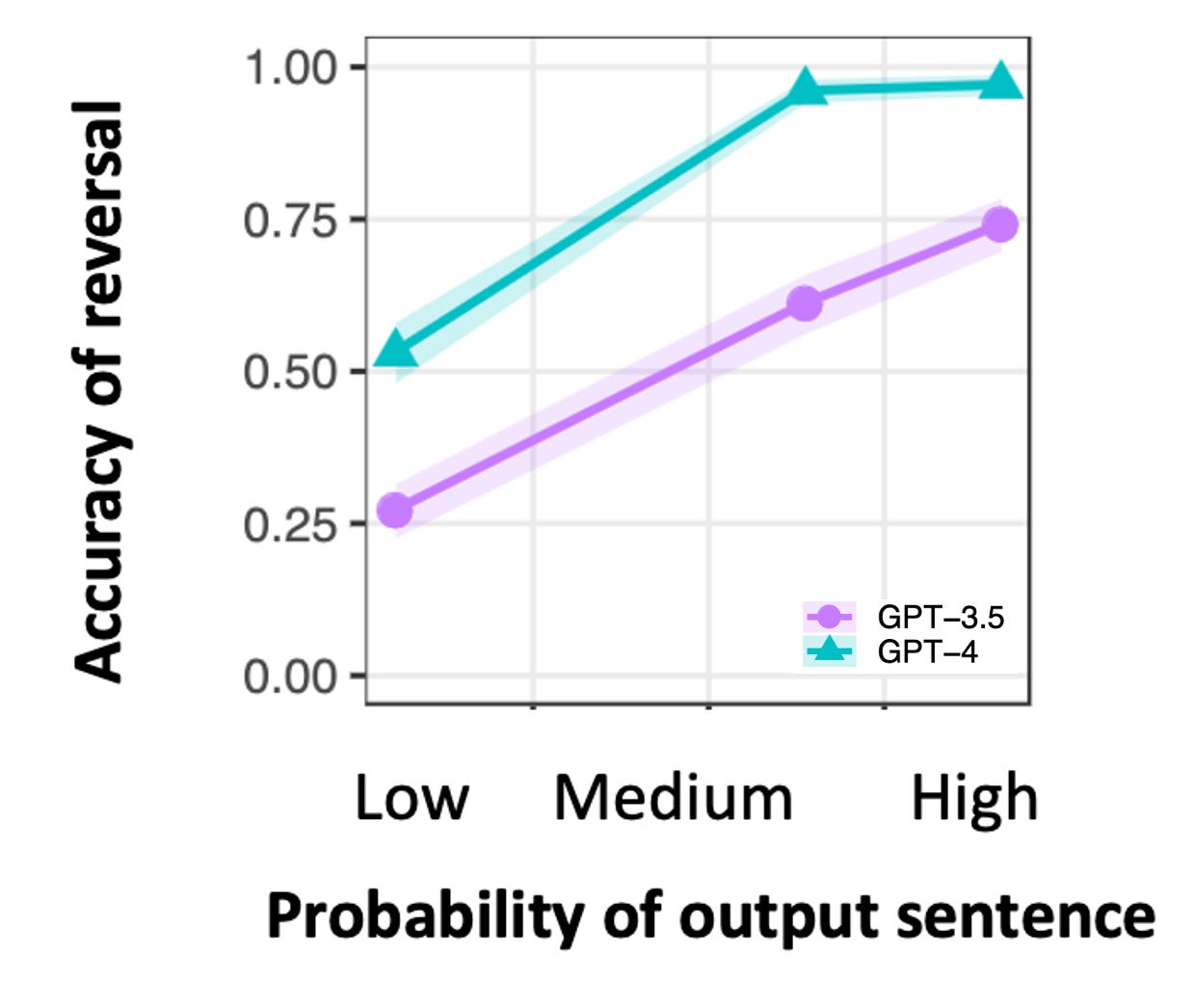
Even though the probability of the output sentence is irrelevant, the LLMs’ training objective of predicting the probable next token leaked into the models’ performance on the task—an ember of autoregression. The paper gives many more examples.
Similar results have been shown in many other papers that “stress-test” LLM reasoning abilities. At the end of this post I give links to various papers on this topic for readers who want to follow up.
In short, LLMs seem to have some ability to reason, but without stress-testing them (e.g., with counterfactual tasks), one can’t conclude that they are reasoning in a general way rather than relying on their training data in ways that won’t generalize to out-of-distribution examples.
In the next post (coming soon) I’ll describe work my group is doing on applying the counterfactual-task paradigm to stress-test claims that LLMs are robust and general analogical reasoners.
Postscript: Papers that evaluate LLMs using counterfactual tasks (or related stress tests)
Wu, Z., Qiu, L., Ross, A., Akyürek, E., Chen, B., Wang, B., Kim, N., Andreas, J., & Kim, Y. (2023). Reasoning or reciting? Exploring the capabilities and limitations of language models through counterfactual tasks. arXiv preprint arXiv:2307.02477.
McCoy, R. T., Yao, S., Friedman, D., Hardy, M., & Griffiths, T. L. (2023). Embers of autoregression: Understanding large language models through the problem they are trained to solve. arXiv preprint arXiv:2309.13638.
Miceli-Barone, A. V., Barez, F., Konstas, I., & Cohen, S. B. (2023). The larger they are, the harder they fail: Language models do not recognize identifier swaps in Python. arXiv preprint arXiv:2305.15507.
Shapira, N., Levy, M., Alavi, S. H., Zhou, X., Choi, Y., Goldberg, Y., Sap, M. & Shwartz, V. (2023). Clever Hans or neural theory of mind? Stress testing social reasoning in large language models. arXiv preprint arXiv:2305.14763.
Verma, M., Bhambri, S., & Kambhampati, S. (2024, March). Theory of Mind abilities of Large Language Models in Human-Robot Interaction: An Illusion? In Companion of the 2024 ACM/IEEE International Conference on Human-Robot Interaction (pp. 36-45).
Srivastava, S., PV, A., Menon, S., Sukumar, A., Philipose, A., Prince, S., & Thomas, S. (2024). Functional Benchmarks for Robust Evaluation of Reasoning Performance, and the Reasoning Gap. arXiv preprint arXiv:2402.19450.
Lewis, M., & Mitchell, M. (2024). Using counterfactual tasks to evaluate the generality of analogical reasoning in large language models. arXiv preprint arXiv:2402.08955.
Thanks, this is the first thing I’ve read that sheds light on the likely difference between reasoning and an LLM simulation of reasoning.
Since we know what LLMs do internally (pattern matching on sequences of undefined tokens), why would anyone expect LLMs to act in any way other than that described here?
(OK, my _opinion_ here is that LLMs are nothing other than an inane party trick*, so this result is exactly what _I_ expect. But, in all seriousness, the whole LLM thing seems wildly overblown.)
From an AI safety standpoint, understanding that LLMs generate exactly and only random recombinations of their training data, would seem to be important. LLMs are useful for generating boilerplate text that can be edited to match the paper being written, can generate code that can be debugged to do the processing required. But can never be trusted to say things that are true. (Again since they have no model of, do no processing to deal with, whatever it is that "true" means.)
*: Party trick seems to be exactly the right technical term for what LLMs do. Generate random text and let the user figure out if it means something. We say "oops, it halucinated" when it says something stupid, and go "koooooooooooooool" when there's a reasonable interpretation of the output. This is exactly what card/tea/palm readers do.