


LLMs and World Models, Part 2
Evidence For (and Against) Emergent World Models in LLMs

This is part 2 of a two-part post on LLMs and “world models.” Part 1 is here.
Evidence For World Models in LLMs: The Case of Othello
Perhaps the most widely cited evidence for emergent world models in LLMs is a pair of studies that focus on the simple board game Othello. In the first study, reported in 2022 by Kenneth Li and others, the authors trained a relatively small transformer network to predict legal moves in the game, and then analyzed the internal activations in that network to see if the transformer had learned a “world model” by virtue of its training on token sequences representing games.
How Othello is Played
A bit of background on Othello: The game is played on an 8×8 board, which starts out with two white and two black tiles arranged in the center as illustrated in (A) below.1
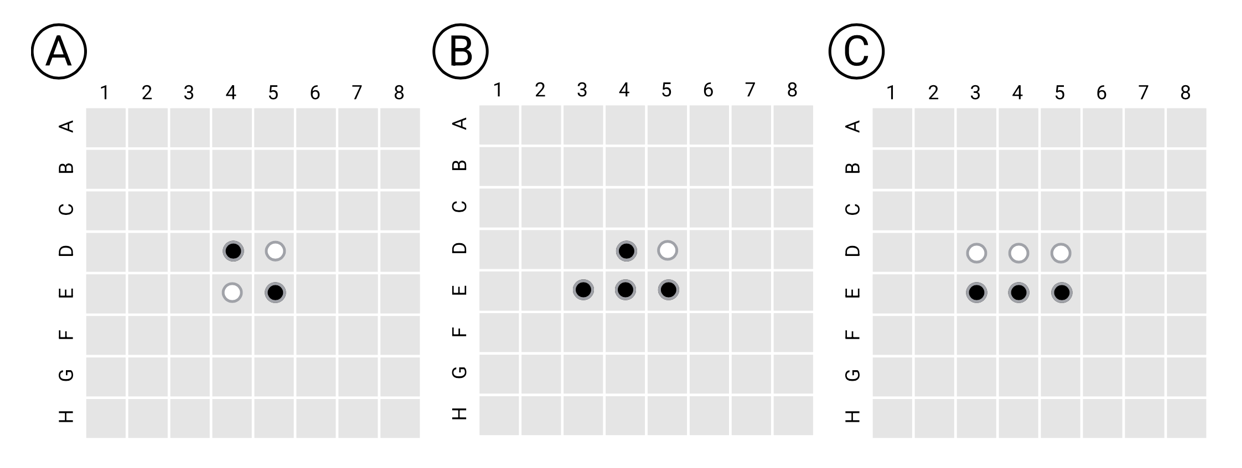
Two players, “Black” and “White,” take turns placing tiles on the board. A tile must be placed so that the player’s color “surrounds” one or more tiles of the other player’s color, and those surrounded tiles flip to the player’s color. For example, in (B) in the image above, Black has placed its tile in square E3, and the previously white tile in E4, now surrounded by two black tiles, has flipped to black. On the next move, White places a tile in D3, and the surrounded black tile in D4 has flipped to white. The game proceeds like this until all possible moves have been made, and the player with the most tiles on the board wins.
Training and Probing OthelloGPT
Kenneth Li and co-authors trained a transformer network, which they called “OthelloGPT,” to input sequences of legal moves, and to output a next legal move in the sequence. Their training process is illustrated below.
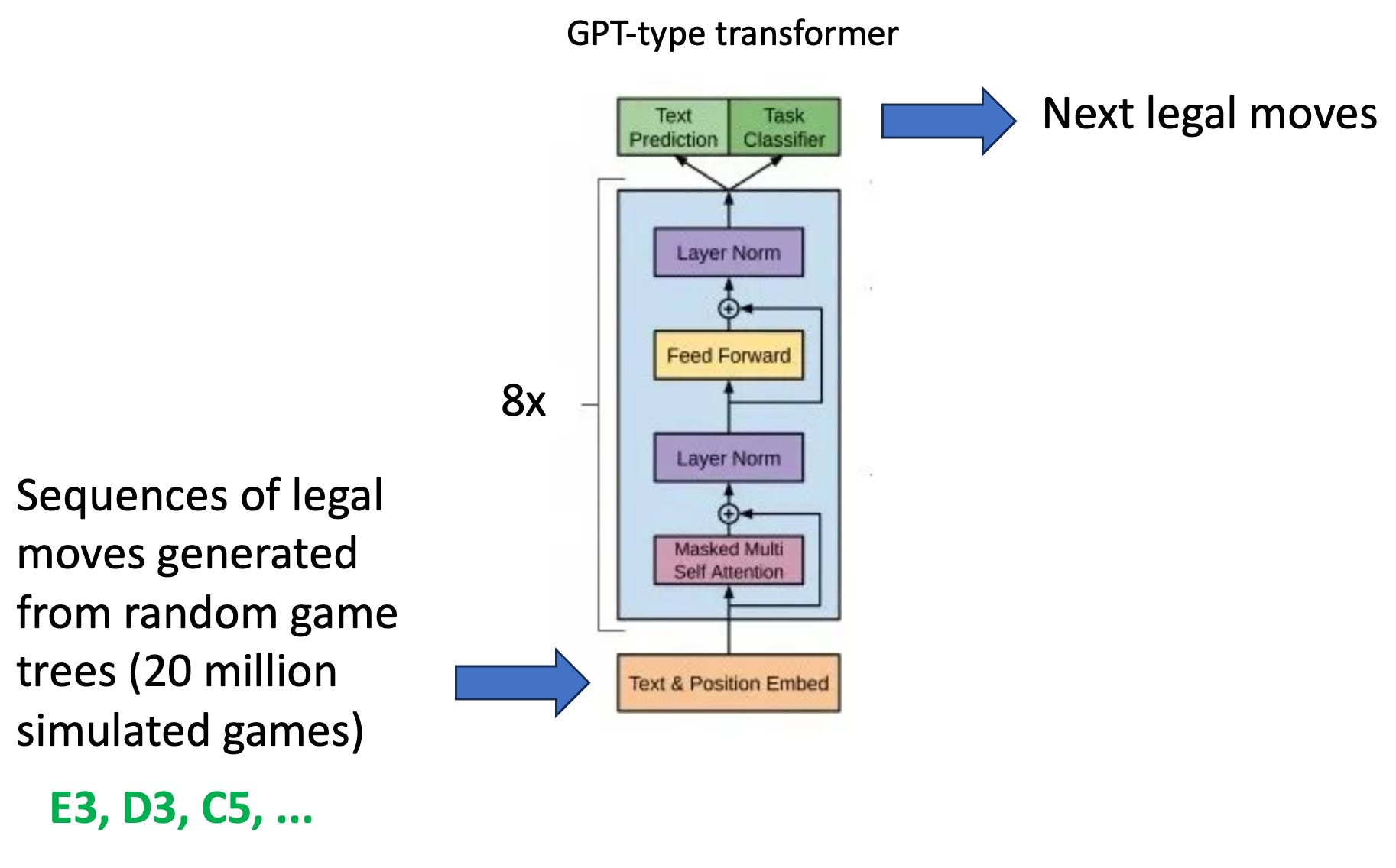
The authors used an Othello game simulator to generate 20 million different game sequences to be used as training. Each of these was a sequence of moves, each of them legal given the previous moves. The moves in each sequence weren’t necessarily good moves; the Othello game simulator just generated sequences of legal moves, without any particular winning strategies.2
The input to OthelloGPT is a sequence of tokens (e.g., E3, D3, C5) each of which represents a legal move in the sequence. The “correct” output for the transformer would be a new legal move in the sequence. Note that this is analogous to typical LLM training to predict the next token in sequences of language tokens, except here the tokens represent moves rather than word parts. And like typical LLM training, the transformer wasn’t told anything about the meaning of the input sequence—it didn’t know that it represented a game played on an 8×8 board, or that there were two players with tiles of different colors, or that the players took turns, or anything else. The transformer saw only the pattern of input tokens.
After training on 20 million such sequences, OthelloGPT was nearly perfect on predicting a token representing a legal move given a sequence of previous moves. The question was, what had the network actually learned in order to perform this task?
Like Ilya Sutskever’s speculation that LLMs develop abstract models of the world strictly from language inputs, the OthelloGPT authors speculated that their transformer had developed an “emergent world model”—a compressed representation of the rules of the game and what the state of the game board would be after any sequence of input tokens—even though it had not been given any information explicitly related to rules or the existence of a board.
To test this speculation, the authors needed a way to look “under the hood” of the transformer. To do this they used a technique called “probing,” which can reveal whether the trained transformer’s internal activations encode the state of the game board.
A probe is a simple classifier—here, a separate machine-learning system that is trained on the transformer’s internal activations to predict the state of the board at different points during a game sequence.
After training OthelloGPT to predict a next legal move in a move sequence, the authors created a training set for such probes. They presented many partial game sequences to the OthelloGPT, and for each input sequence they recorded the network’s vector of internal activations at each of its eight layers. If OthelloGPT has an implicit world model, these activations should somehow encode what the contents of each board square would be, given the sequence of moves represented in the input. These vectors were used as the training set for probes; the goal was to train probes to input these vectors and output the state of the board.
As illustrated below, the authors created 64 different probes, one for each board square. Each probe is a simple linear classifier that inputs the activation vector from a given layer and outputs its prediction for the current contents of that square—“black,” “white,” or “empty”. The authors trained each probe to give the correct classification of its corresponding board square given the activations, and then tested the probes on activations resulting from new sequences not seen in the training data.

The idea is that since linear classifiers are so simple, if they can predict the correct board state from the transformer activations, those activations much encode that state in a very easy-to-decode way—that is, they provide a representation that can be used to easily answer questions about the dynamic state of the Othello board, just like the orrery allows us to easily answer certain questions about the dynamic positions of planets.
However, a snag arose: the linear probes trained by the authors didn’t work very well in predicting the board state. So, the authors tried training more powerful nonlinear probes—in particular, neural networks with a hidden layer. These worked much better in predicting the board state—for example, when activations from transformer layer 7 were given as inputs, the trained probes were able to correctly predict the corresponding board state with about 98% accuracy.
But wait—this is far from cut-and-dried evidence of the transformer having developed a “world model”. The problem is that nonlinear probes are too powerful at learning patterns. The credit for predicting the board state might not be due to the transformer, but to the probe itself!
An important point to remember here: OthelloGPT was not trained to predict the board state. It was trained only to input a sequence of moves and predict a next legal move. However, the nonlinear probe was directly trained to predict the board state from OthelloGPT’s activations. So if there is anything encoded in those activations that a nonlinear probe can use to predict the board state, it will succeed. For example, suppose that the transformer’s internal activations don’t encode board states at all, but are merely compressed versions of the input sequence of tokens. It can be shown that a sufficiently powerful nonlinear probe, given these activations, could learn to decode the input sequence and map it to the state of a particular board square. Importantly, a linear probe is not powerful enough to do this.
Me: Not So Impressed. Others: Impressed
For this reason, after reading the paper by Li et al., I wasn’t impressed with the evidence for “emergent world models” in OthelloGPT.
However, other, very prominent, AI researchers were impressed. Chris Olah, co-founder of Anthropic, tweeted this:

And Andrew Ng, a deep-learning pioneer and co-founder of the Google Brain team, tweeted this:

Linear Probes Work After All!
Shortly after the Li et al. paper came out, another researcher made an announcement that made me rethink my position. Neel Nanda, now at Google DeepMind, showed that there are linear probes that can learn to map OthelloGPT’s internal activations to board states. Nanda and collaborators basically followed the same experimental procedure as I described above for the original paper: the linear probes were trained on internal activations to classify the contents of each board square, but with one modification: instead of classifying each square as “black,” “white,” or “empty,” they classified the contents as “mine,” “yours,” or “empty. That is, if the input activations came from a sequence in which the last move was Black’s, “mine” meant black and “yours” meant white. The reverse was true if the input activations came from a sequence in which the last move was White’s.
This change made all the difference: Now, linear probes receiving input from layer 7 activations were able to predict the board state with a whopping 99.5 % accuracy.
Why did changing from “black, white, empty” to “mine, yours, empty” make such a big difference? It seems that one of OthelloGPT’s attention heads learned to keep track of alternating moves, and that the meaning of the internal activations depended on which player had moved last in the input sequence.
Does OthelloGPT Have an Emergent World Model?
I was quite impressed by Nanda et al.’s paper (and still am!), even more so after I (along with some collaborators) tried to disprove their claims, and failed. Moreover, other groups showed similar evidence of world models in transformers, such as in learning to predict legal moves in chess and learning to navigate simple mazes.
But the question still remains: does this all mean that OthelloGPT and other such transformers have indeed developed implicit world models? If so, what kind of world models have they developed?
Let’s go back to the part of this post where I tried to define “world models.” I said this:
“[T]hey capture something about the world that is causal and abstract (or compressed) rather than simply based on large sets of statistical associations; they don’t require too much work for the agent to use (“algorithmically efficient”) and are relevant to tasks the agent performs.”
Nanda et al. showed that OthelloGPT’s encoding of the state of the board was causal: they showed that the system used the implicit state-of-the-board information to perform its task of predicting legal moves. To show this, they changed the state of the system’s implicit state-of-the-board encoding (by changing the activations encoding the state of the board) and showed that this changes OthelloGPT’s legal move predictions in consistent way.3
So, OthelloGPT’s internal activations certainly capture something about the world that is causal and relevant to the task, but it remains to be shown that its internal representation of the board is abstract and “algorithmically efficient”—the kind of mental model of an Othello game that humans would likely use to dynamically imagine and reason about the state of the board.
World Models Versus Bags of Heuristics
The OthelloGPT world-model story faced a new complication when, in mid-2024 a group of student researchers released a blog post entitled “OthelloGPT Learned a Bag Of Heuristics.” The authors were part of a training program created by DeepMind’s Neel Nanda, and their project was to follow up on Nanda’s own work, and do careful experiments to look more deeply into OthelloGPT’s internal representations. The students reported that, while OthelloGPT’s internal activations do indeed encode the board state, this encoding is not a coherent, easy-to-understand model like, say, an orrery, but rather a collection of “many independent decision rules that are localized to small parts of the board.” As one example, they found a particular neuron (i.e., neural network unit) at one layer whose activation represents a quite specific rule: “If the move A4 was just played AND B4 is occupied AND C4 is occupied, then update B4 and C4 and D4 to ‘yours’ [assuming the mine, yours, or empty classification labels]”. Another neuron’s activation represents the rule “if the token for B4 does not appear before A4 in the input string, then B4 is empty.”
These are examples of many specific, localized heuristics that OthelloGPT seems to use. Any individual rule is not always correct, and in some cases these rules contradict one another, but the collective activations of large numbers of neurons representing different heuristic rules, each of which is contributing to activations of other neurons, almost always results in the correct predictions being made for the board state. In summary, “we conjecture that Othello-GPT computes whether cells are ‘mine’ or ‘yours’ by aggregating many heuristic rules, rather than implementing a crisp algorithm with a short description length.”
If this conjecture is correct (and this report has not yet, as far as I know, been peer-reviewed), then OthelloGPT’s implicit representations are more like Ptolemy’s epicycle model than a modern orrery. It’s a bag of heuristics that results in mostly accurate predictions, but is not algorithmically efficient (i.e., easy to use to answer questions) or abstract (i.e., it’s quite specific to this particular version of Othello, and can’t be easily adapted to new situations, for instance playing Othello on a 10x10 board).
Other papers have found similar collections of heuristics likely underlying the (imperfect) ability of transformers to solve arithmetic problems and to perform route-planning and other tasks. It’s possible that such collections of heuristics also are driving the chess-playing and maze-solving abilities I mentioned above. Neural networks with large numbers of parameters can potentially encode huge collections of such heuristics, which produce behavior that looks like the kind of world model a human might have, but that ends up being brittle when encountering sufficiently novel situations. Today’s LLMs are clearly much less brittle than the neural networks of “before times” that I talked about in Part 1 of this post, but they still exhibit brittleness, possibly due to a similar reliance on bags of heuristics, albeit at a much larger scale.
Humans probably use a mix of abstract world models and bags of heuristics for problem-solving as well, but I think it’s likely that humans don’t have the same capacity as today’s LLMs to learn enormous numbers of specific rules. I’d guess that it’s actually our human limitations—constraints on working memory, on processing speed, on available energy—as well as our continually changing and complex environments, that require us to form more abstract and generalizable internal models. Perhaps we will need to constrain and challenge our machines in similar ways to get them to “think” more abstractly and to be better at generalizing outside of their training data distributions.
Conclusion
The claims of emergent abstract world models in LLMs are not yet supported by strong evidence. There is some evidence of such world models arising in transformers trained on narrow domains (Othello, chess, mazes, etc.) but also evidence that their abilities arise not from human-like internal models but from large “bags of heuristics”. Moreover, the notion of “world model” itself is not rigorously defined; when considering whether an agent has a particular kind of world model, we should ask what kinds of questions such a model should be able to answer, how easy or hard it should be for the agent to get answers from the model, and to what extent we would expect that the model would allow the agent to adapt to novel situations.
From https://arxiv.org/abs/2210.13382.
The authors also experimented with using strategic game sequences, generated by human players, as training data, but this approach didn’t work as well for the goal of predicting legal moves.
Li et al. also demonstrated the causal influence of the internal board-state-encodings on OthelloGPT’s prediction of legal moves.
Really liked this passage:
I’d guess that it’s actually our human limitations—constraints on working memory, on processing speed, on available energy—as well as our continually changing and complex environments that require us to form more abstract and generalizable internal models.
An analogy I'd like to suggest is to consider the difference in the way birds and airplanes fly. Birds are far more efficient in using available power but airplanes have so much power to spare that it doesn't matter.
Amazing post, as always :) More evidence (at least in my interpretation) for the "bag of heuristics" explanation can be found in On the Geometry of Deep Learning by Prof. Balestriero and colleagues, which discusses how these models effectively rely on enormous, piecewise-linear tilings to collectively solve tasks – https://arxiv.org/abs/2408.04809.