

Why the Abstraction and Reasoning Corpus is interesting and important for AI
Why the Abstraction and Reasoning Corpus is interesting and important for AI

AI’s Most Important Open Problem: Forming Concepts and Abstractions
In their proposal for the 1956 Dartmouth summer workshop, John McCarthy et al. summarized their plan for a “2 month, 10 man study of artificial intelligence”: “An attempt will be made to find how to make machines use language, form abstractions and concepts, solve kinds of problems now reserved for humans, and improve themselves.” While it turned out that the two months they had allocated wasn’t sufficient, in the seven decades since the workshop, enormous progress has been made on machine language processing, problem-solving, and learning. Much less progress has been seen on forming concepts and abstractions.
Consider, for example, the “simple” concept on top of. In its most concrete definition, an object or location being “on top of” another object or location refers to a spatial configuration (“the cat is on top of the TV”) but the concept can be abstracted in any number of ways: being on top of a social hierarchy, on top of one’s game, on top of the world (i.e., extremely happy), staying on top of one’s work, singing at the top of one’s voice, being born at the top of a decade, and so on.
Forming and abstracting concepts is at the heart of human intelligence. These abilities enable humans to understand and create internal models of the world—often involving physical knowledge or experience, such as “something on top of something else”—and to use these models to make sense of new information, often via analogy, and to decide how to behave in novel situations. I particularly like the definition of “concept” given by the cognitive psychologist Lawrence Barsalou: “A concept is a competence or disposition for generating infinite conceptualizations of a category.” And the driving force for generating such conceptualizations is analogy, such as when we map the spatial notion of “on top of” to a temporal, vocal, or social notion. Douglas Hofstadter put it this way: “A concept is a package of analogies.”
In my view, AI’s most important (and enduring) open problem is being able to form concepts and abstractions. Even the simple spatial concept of “on top of” seems to be challenging for today’s state-of-the-art language and image generation models (see Figures 1–2). Such brittleness has real-world implications for the robustness and reliability of systems such as AI-powered search engines, image-recognition methods, and autonomous robots that need to understand concepts and their abstractions in the real world.
Figure 1: Given the prompt “A television on top of a cat”, neither DALL-E nor Stable Diffusion is able to generate the correct configuration of television and cat.

Figure 2: ChatGPT (top) and GPT-3 text-davinci-003 (bottom) both fail when asked to reason about a spatial configuration involving “on top of” .
There has been considerable research on getting AI systems to make abstractions and analogies, a lot of it using idealized domains such as Raven’s Progressive Matrices or Bongard Problems. My 2021 paper Abstraction and Analogy in Artificial Intelligence surveys some of this work.
The Abstraction and Reasoning Corpus
In this post I want to talk about one specific idealized domain, the Abstraction and Reasoning Corpus, created by François Chollet. I’ll talk about what the domain is, why I think it’s particularly interesting as a research program for AI, and why it’s still quite challenging, and perhaps impossible, for current AI systems, including everyone’s favorite large language models. In a subsequent post, I’ll talk about some of the work my own research group has been doing related to this domain.
Figure 3: A sample ARC task. The challenge is to infer the abstract rule governing the demonstration transformations and apply it to the test input.
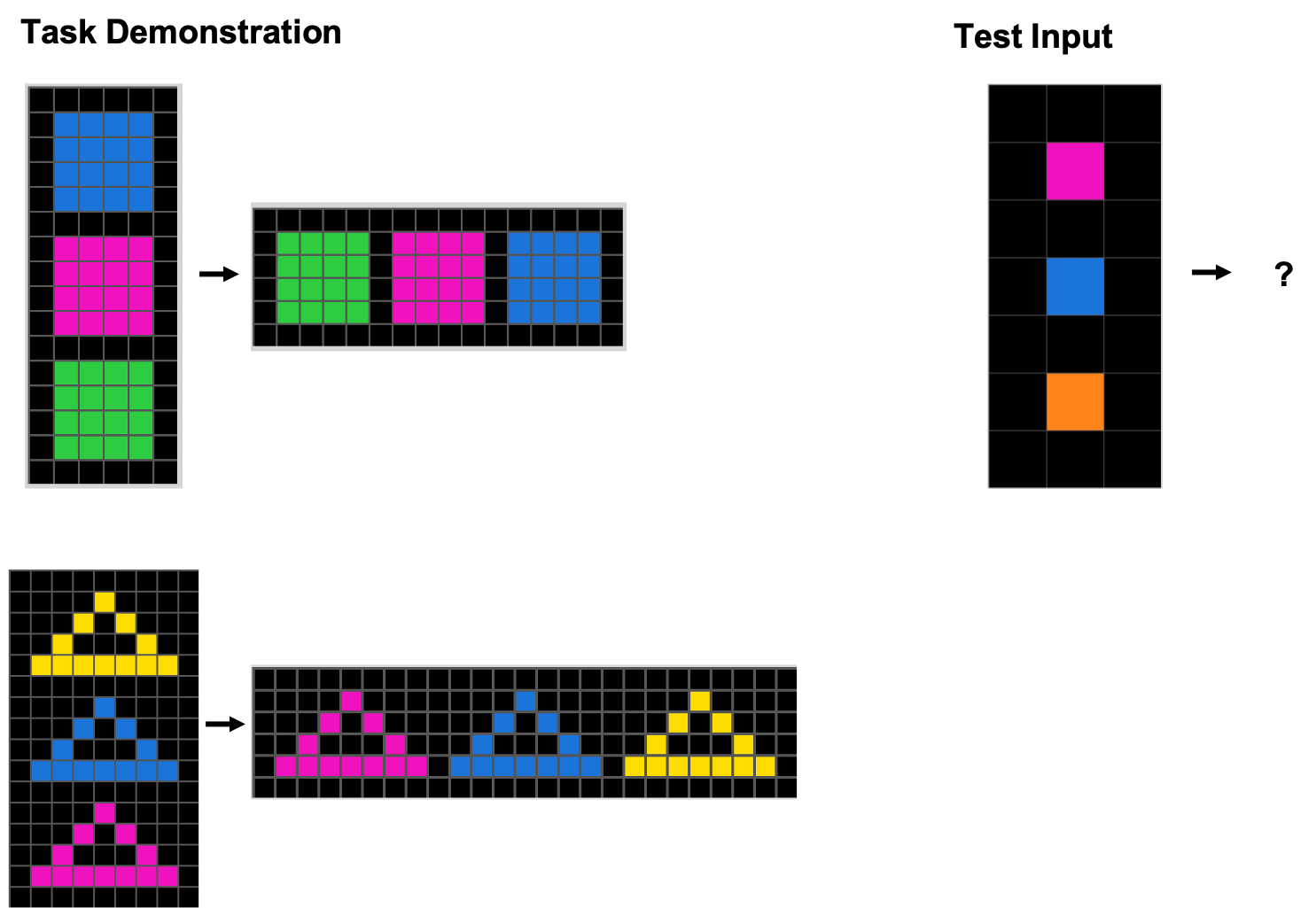
Figure 3 gives a sample ARC problem (or “task”). Each problem consists of one or more task demonstrations, in which one grid of colored pixels is transformed into a new grid. In Figure 3 there are two demonstrations. The task is to infer the rule (or abstract concept) behind the transformations and apply the analogous transformation to the test input grid.
The ARC domain is very open-ended: grids can be of any size and dimensions, and there are ten possible colors for the grid squares (including black). While the sample task shown in Figure 3 is likely easy to solve for most people, ARC tasks can be more complex, such as the one shown in Figure 4. You might want to take a crack at this task before reading on.
Figure 4: A more complex ARC task.

To solve the task in Figure 4, you need to have some basic concepts—recognizing connected pixels as “objects” and discerning abstract commonalities of object shapes. Roughly, “L-shaped” objects are colored blue, “U-shaped” objects are colored pink, and “h-shaped” objects are colored red, regardless of their size, rotation, symmetry, or position in the grid.
Chollet created 1,000 ARC tasks, and released 800 of them. Two hundred tasks were reserved as a “hidden” test set.
In his paper describing the goals of ARC, Chollet cites the work of developmental psychologist Elizabeth Spelke on the “core knowledge systems” that are either innate or developed early on in humans (and likely some non-human animals). These core systems include:
(1) objectness: the knowledge that the world can be parsed into objects that have certain physical properties;
(2) numerosity: knowledge of small quantities and notions of “smallest,” “largest,” “greater than,” “less than,” etc.;
(3) basic geometry and topology, such as knowledge of lines, simple shapes, symmetries, containment, and copying;
(4) agents and goals: knowledge that some entities are agents who have their own intentions and act to achieve goals.
In creating ARC tasks, Chollet assumed the first three as “priors”—the only knowledge that should be necessary to solve these tasks.
Chollet’s ARC tasks are beautiful to look at and fun (and often quite challenging for humans) to solve. But what’s important about the ARC domain is that it captures important aspects of abstraction and analogy in a rich and open-ended way, yet is completely explicit about what prior knowledge is needed for solving problems. Moreover, the domain is fundamentally about “few-shot learning”—each task has only a few examples from which an abstract rule must be inferred. An AI system that could solve ARC domain problems in general would, I think, be a significant step toward one that could achieve humanlike abstraction and analogy-making in the real world.
AI’s State-Of-The-Art on ARC
So how does current AI stand with respect to ARC problems?
To find out, Chollet created a competition on the Kaggle website (a platform that organizes many machine learning competitions). The contenders were given 800 of Chollet’s 1,000 ARC tasks—not nearly enough for even a small neural network to train on. Half of the 200 “hidden” tasks were used to evaluate the competing programs. For each task, a program was allowed to generate three candidate answers, and if one of them was correct, the task was considered to be solved correctly.
Using this accuracy metric, the best-scoring program was able to solve about 20% of the hidden tasks. However, rather than actually forming abstract, generalizable concepts, the best programs employed a heuristic search through pre-defined grid transformations, and even their authors agreed that such an approach is not likely to generalize broadly to new tasks.
Can Large Language Models Solve ARC Tasks?
A question that comes up often with respect to ARC and other idealized domains: aren’t today’s large language models smart enough to perform these tasks?
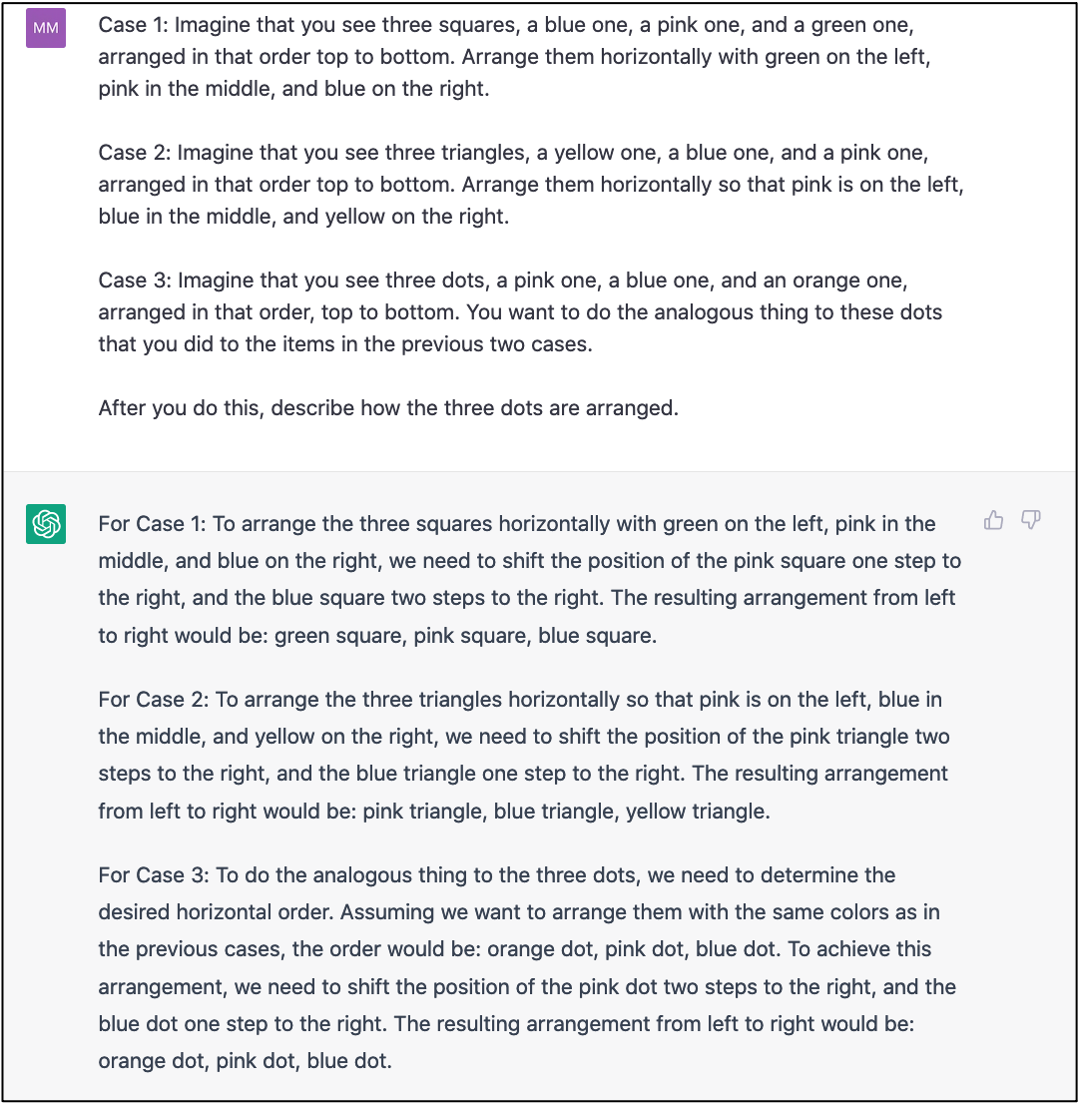
The answer is “no.” ARC tasks are visual, so are not amenable to text-only language models such as GPT-3. One could “cheat” by describing the problem in English to a language model, but of course having a human create such a description amounts to pre-solving a good part of the task. This said, even when they are provided with such a description, language models can’t always solve the task; they are known to perform badly at spatial reasoning tasks. As an example of this, I gave an English description of the task in Figure 3 to both ChatGPT and GPT-3, neither of which solved the task correctly (Figure 5). It’s possible that this kind of performance will improve with larger models, and that eventually multimodal “foundation” models will be able to solve such problems, but I remain skeptical. I have heard that the next generation of GPT models (and language models from other companies) will be multimodal (able to deal with both text and images), so we may be able to test them on ARC tasks in the near future.
Figure 5: An English description of the transformations and test input in the ARC task of Figure 3, given to ChatGPT. ChatGPT’s response, though wordy, is incorrect.
Crowdsourcing and Competitions for the ARC Domain
In summary, ARC tasks remain an open challenge in AI. Chollet and his collaborators have launched a platform for crowdsourcing the creation of new ARC problems and a new competition that will take place during 2023. People who care about the future of robust AI should pay attention.
In the next post, I will describe some of the work being done on ARC by my collaborators and me. Stay tuned!
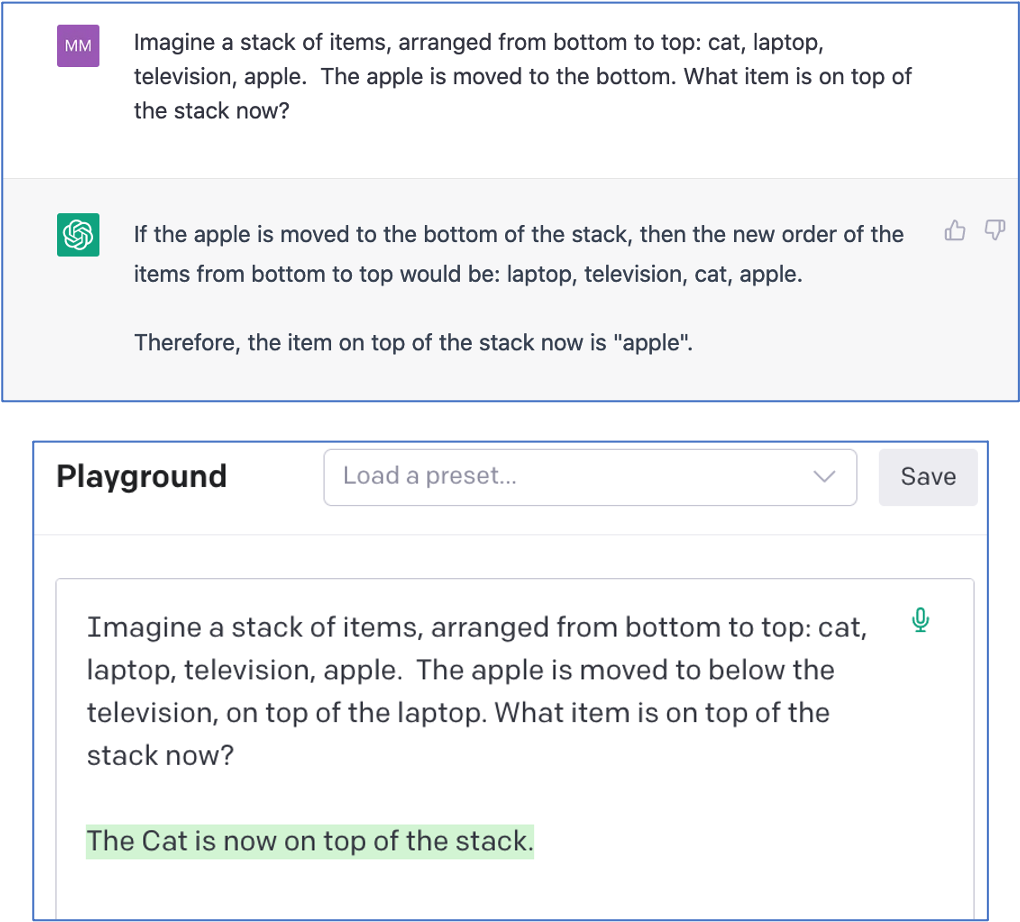
My assumption is that mental imagery is a critical capability that humans use for many of the problems you describe. As long as LLMs only process language, their only hope is to find associations to language descriptions of similar problems and fake it. One would hope that someday these systems would be extended to have mental imagery components (as found in cognitive architectures), not to mention episodic memory!
I enjoyed this article is a lot, thank you! Since GPT-4 was released since its publication, I thought I'd try the stack-of-items prompt – and unlike the GPT-3.x models, 4 does in fact pass. I won't try to draw far-ranging conclusions from that one data point, but it seems a meaningful one nonetheless.
Q: Imagine a stack of items, arranged from bottom to top: cat, laptop, television, apple. The apple is now moved to the bottom. What items is on top of the stack now?
A: If the apple is moved to the bottom of the stack, the new arrangement from bottom to top would be: apple, cat, laptop, television. The item on top of the stack now is the television.
(Bard gets it hilariously wrong...ish? "The items on top of the stack now are the cat and the laptop. The apple was originally on the top of the stack, but it was moved to the bottom. This means that the cat and the laptop are now on top of the stack.")