

In this post I’m going to go into the weeds, describing how some people are trying to win a big $$$ prize for solving a still-wide-open AI challenge, the “Abstraction and Reasoning Corpus,” and what it all means.
Remember ARC?
As you might know, I’m a big fan of the Abstraction and Reasoning Corpus (ARC), created by Francois Chollet. As I wrote about in a previous post, ARC addresses few-shot abstraction, analogy, and generalization—some of the most important capabilities for human cognition that are largely lacking in today’s AI systems.
ARC is a set of analogy puzzles in which the solver must infer the abstract rule underlying a small set of grid transformations, and apply that rule to a new grid. Here are three examples from Chollet’s corpus (each puzzle is called a “task”):
Example 1:
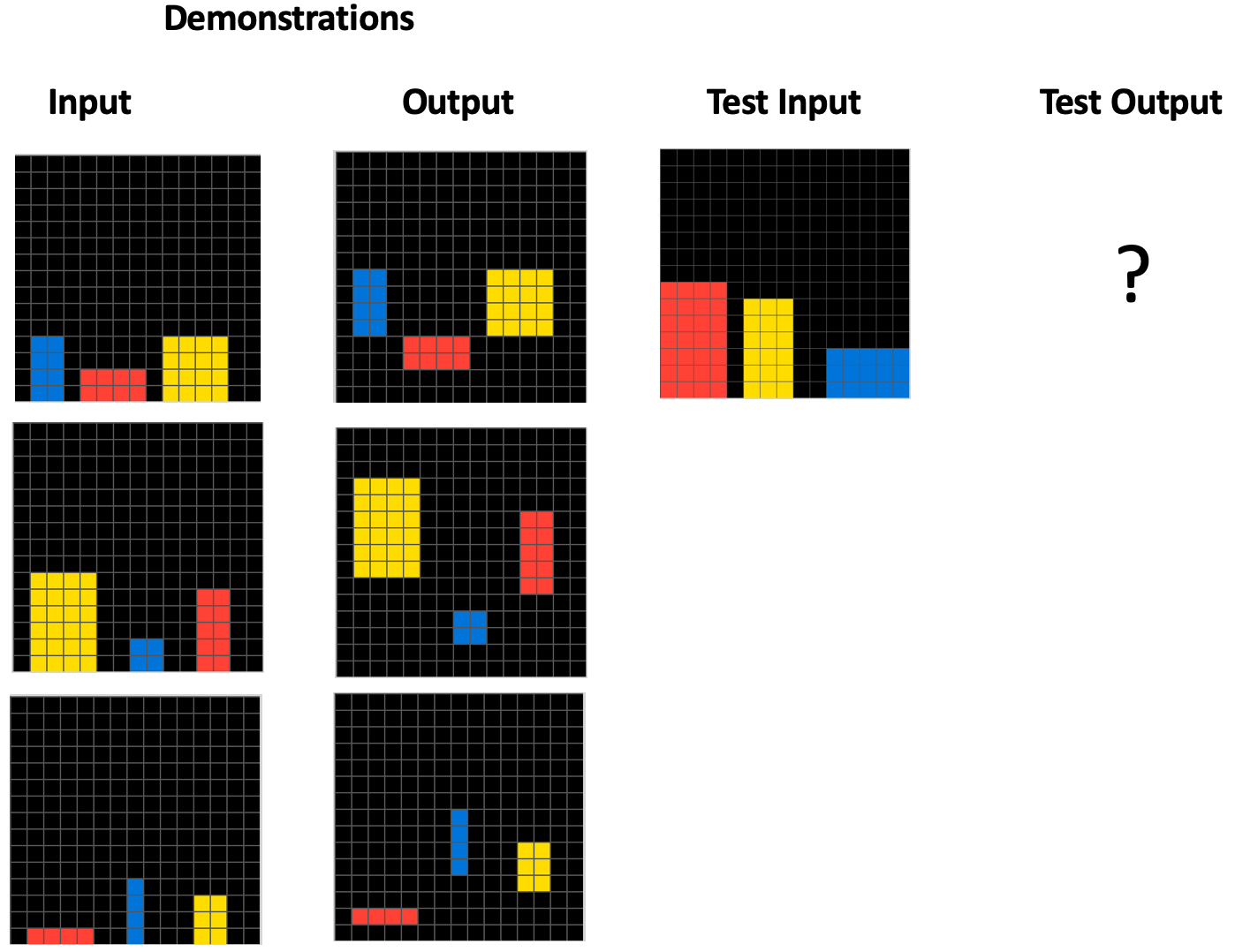
Example 2:

Example 3:
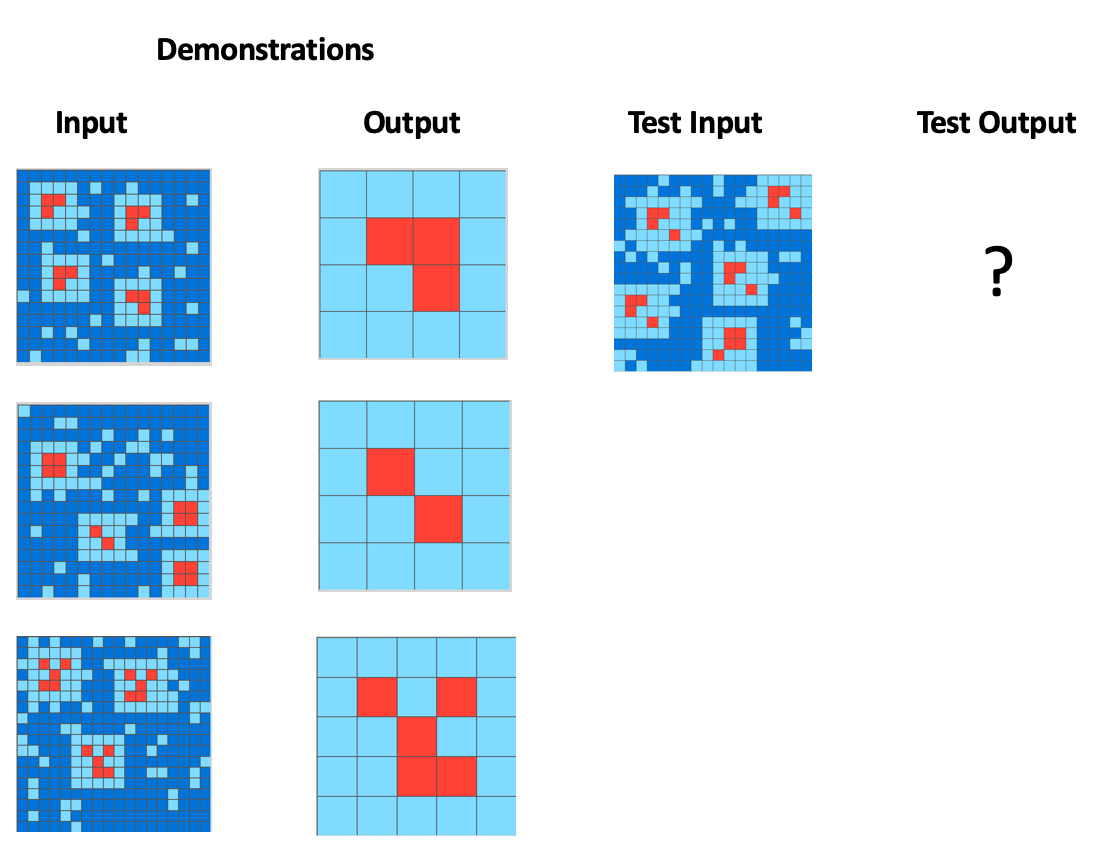
Each of these example tasks has three “demonstrations” and one test input. To solve the task, you need to generate a new grid that transforms the test input using the same abstract rule used in the demonstration transformations. I’ll let you try to solve these tasks; you can find the answers at the end of this post.
The corpus created by Chollet contains 1,000 tasks:
The training set contains 400 of the easier tasks.
The evaluation set contains 400 more difficult tasks.
There is also an unpublished private evaluation set of 200 tasks.
If you’re trying to create a program to solve ARC tasks, you would use the training set to either train your system or to figure out what concepts to build into it, and you would then use the (public) evaluation set to see how well it does, and perhaps improve your training or programming strategies.
The private evaluation set (or a subset of it) is used to score programs submitted to ARC competitions, and is never revealed publicly.
Humans Versus Machines on ARC
How good are humans at the ARC tasks? Chollet posited that “A typical human can solve most of the ARC evaluation set without any previous training,” but surprisingly, this hasn’t been tested (at least not to my knowledge).
A 2021 study from a team at NYU tested Amazon Mechanical Turk workers on forty randomly selected tasks from the ARC training set. On average about 84% of these people got each task correct. This number is now taken as a rough estimate of human performance (though it’s likely an overestimate for the harder evaluation sets).
Over the last several years there have been a few different competitions to develop AI programs to solve ARC tasks. In the 2020 Kaggle competition, a subset of 100 tasks from the private evaluation set was used to score program entries. The winning method got about 21% of the tasks correct. An ensemble of the top two methods scored 31%. In comparison, large language models, without a lot of prompt engineering and other interventions, score quite poorly: 10% or so on the training set.
Additional competitions were held, with new approaches bringing the state-of-the-art (SoTA) on the 100-task private evaluation set to 34%. This is still quite a gap between the best AI systems and humans, which makes the ARC challenge interesting, especially in an age when many AI proponents are predicting near-term “artificial general intelligence” (AGI).
Until recently, while ARC had a small devoted fan base, most people in AI barely knew of or paid attention to this challenge. But a couple of months ago, many more people started paying attention, on account of a new competition with $1 million in prize money.
The $1M ARC-AGI Prize
In June, 2024, Mike Knoop, an entrepreneur and head of AI at Zapier, joined forces with Chollet to spur interest in ARC. “AGI progress has stalled. New ideas are needed”, they wrote.
Together, Knoop and Chollet set up the ARC Prize, an annual competition for AI systems, which offers both “Progress Prizes” up to $25,000 for top-performance during 2024, and a $500,000 grand prize for the program that scores 85% or higher on 100 tasks from the private evaluation set. During the test, contestant programs are also limited to 12 hours of run time, with no internet access.
Oh yeah, they also rebranded ARC as “ARC-AGI”, which I’m not a fan of, since I don’t love the term “AGI,” and I don’t think that solving ARC is necessarily the golden ticket to achieving AGI, whatever AGI is. But no one is asking me for naming advice.
Why did they set 85% as the threshold score for the grand prize? Actually, I’m not sure. It’s related to the 84% from that NYU study, and (from the ARC Prize website), “[w]e set the Grand Prize score goal of 85% because it is high enough to consider ARC-AGI as solved, but low enough to acknowledge it is imperfect.”
Can LLMs Solve ARC After All?
A week after the ARC Prize was announced, a tweet thread (oops, an X thread) from AI researcher Buck Shlegeris shocked many people working on ARC:

and

So, this thread claimed, in a single week, using GPT-4o, Greenblatt had achieved 51% score on the ARC “test set”, which was far above the previous state of the art of 34%.
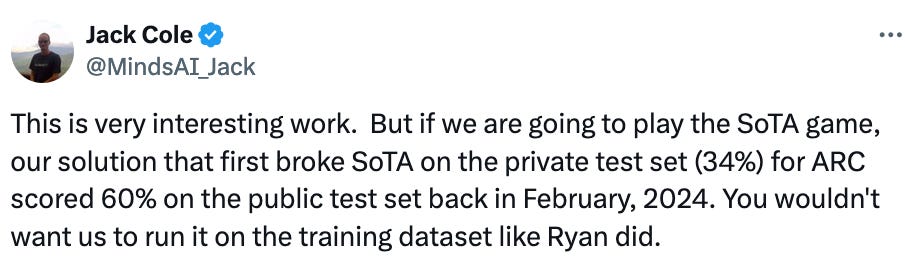
It turned out that Shlegeris and Greenblatt were confusing the public evaluation set with the private one. Greenblatt’s method had scored 51% on the public evaluation set (or, as I describe below, a subset of it) not the private one, and that’s a big difference. Jack Cole, who leads the “MindsAI” team that had earlier obtained 34% on the private set, posted this in reply to Shlegeris:
Greenblatt’s method couldn’t be run on the private evaluation set because it violated two rules of the competition: it required internet access (to use the GPT-4o API) and required more than the allotted 12 hours of run time.
But it’s worth explaining how Greenblatt’s method works, since it’s an interesting approach and at the same time it brings up the question of how much brute-force computation can be used before the approach violates the spirit of the ARC challenge: that is, not merely to solve ARC but to do so via a method that will lead to progress in AI more generally.
The Generate-Test-Revise Approach To ARC
Greenblatt, who works on AI at Redwood Research, sketched his method in a blog post, titled “Getting 50% (SoTA) on ARC-AGI with GPT-4o.”
Solving an ARC task involved several steps: first figuring out how to prompt GPT-4o to generate Python programs to solve the task, then repeatedly using the prompt to generate many different Python programs, and then prompting the system to revise the most promising programs, and then having the most promising revised programs “vote” on the answer. Here’s a sketch of these steps:
Prompting
Greenblatt created a very long prompt, giving both an image version and multiple text representations for each grid in the task, as well as representations of differences between grids. (The blog post did not give the actual prompt he used.)
The prompt also “instruct[ed] GPT-4o to reason about what the transformation is, reason how to implement the transformation as code, and then finally actually implement the transformation in code.”
The prompt also included “several carefully handwritten examples of step-by-step reasoning to actually get GPT-4o to do this reasoning somewhat effectively.”
“The resulting prompt is usually around 30k tokens long including images.” In other words, the prompt is around the same length as a 50-page masters thesis.
Generating Many Python Programs
Following instructions and examples in the prompt, GPT-4o’s response is a Python program that performs a grid transformation. The hope is that the program transforms each of the demonstration input grids correctly into their outputs, and will likewise transform the test input grid into the correct solution to the task. The likelihood that such a generated program will be correct (or near correct) is generally small, so the prompting process has to be repeated, a lot of times.
Greenblatt’s method used his prompt to get GPT-4o to generate about 5,000 programs for a given task.
Revising the Most Promising Programs
Greenblatt’s method selected the most promising 12 programs out of these 5,000 (he doesn’t say in the post how this promise is determined; it might be how close the output of these programs comes to the correct outputs in terms of grid overlap, or some other measure), and, for each of them, further prompted GPT-4o, showing it the difference between this program actually outputs on the demonstrations and what the correct output should be, and prompting it to revise the program to make it generate the correct output. For the 12 selected programs, this generated 3,000 new programs.
Voting
Finally, assuming some subset of these programs gets the demonstration outputs correct, Greenblatt’s method generates three possible solutions by taking a “majority vote” over the programs in this subset when run on the test input. (Greenblatt doesn’t give details on how this voting works.)
Greenblatt notes that the scores of “71% on the training set” and “50% on the public evaluation set” actually comes from running on only a sample of 100 (out of 400 total) tasks from each of those sets:
“To decrease cost and to allow for having a subset to iterate on (especially for the train set!), I only ran my solution on a randomly selected set of 100 train and 100 test problems. The resulting standard error of the mean is reasonably tight (5%), but this means my results might be slightly overoptimistic.”
Greenblatt’s method—essentially generate, test, and revise—is similar to recent approaches to using LLMs for mathematics, such as Google DeepMinds’s FunSearch and AlphaProof.
Scaling up the number of programs sampled at the different stages, or additional prompt engineering, or additional refinement steps, might very well increase the score on ARC. But to my mind it violates the spirit of the ARC challenge, not only because it requires so much computation and human engineering of prompts. My interest in ARC is its supposed ability to test humanlike abstraction (and understanding of core knowledge concepts), and it’s not clear to me that this method actually does any abstraction.
To me, this is reminiscent of the comparison between computer and human chess players. Computer players get a lot of their ability from the amount of look-ahead search they can do, applying their brute-force computational powers, whereas good human chess players actually don’t do that much search, but rather use their capacity for abstraction to understand the kind of board position they’re faced with and to plan what move to make.
The better one is at abstraction, the less search one has to do. It would be disappointing, at least to me, if ARC can be solved largely via brute-force domain-specific search rather than via more general and humanlike abstraction.
The Actual State of the Art
After the 2020 competition on Kaggle, the state-of-the-art score on the ARC private evaluation set didn’t increase for a few years, until 2023, when a team called MindsAI scored 34%. Since then, the team has remained at the top of the leaderboard, gradually improving their method; at the time of this writing, they still hold first place with a score of 43%.
The details of this team’s method haven’t been published yet, but members of the team have described the basic idea in interviews and podcasts. Here’s my understanding of how it works.
Like Ryan Greenblatt’s method, this approach uses a pre-trained LLM to generate programs that perform grid transformations to solve a given task. But instead of relying on very long prompts to instruct the LLM about the ARC domain, the MindsAI team first fine-tunes the LLM on ARC tasks—training the model’s weights to generate code to solve tasks in the training set. But here’s a problem: the training set contains only 400 tasks: not nearly enough to finetune a large neural network. MindsAI’s solution is to automatically create large numbers of new ARC tasks that are variations of the original training tasks, and use these to augment the training set for fine-tuning the LLM.
With the fine-tuned LLM in hand, MindsAI uses another important trick. When the fine-tuned model is given a new task to solve, the trick is to automatically augment the task’s demonstrations and do additional fine-tuning on these specific transformations. This helps transform each task from a few-shot (e.g., three demonstration) learning task to a larger-shot (many-demonstration) task, which in principle should make the task easier to solve. This test-time augmentation method has been called “active inference” (not to be confused with a different use of the term).
The MindsAI group also did some prompt engineering for their method. The details haven’t been revealed yet, but fortunately for us it will be at some point: releasing code is a requirement of submitting entries to the ARC prize competition.
As far as I can tell, the rising score of this method, from 34% to 43% over the course of several months, is largely due to increased computation use in order to generate and fine-tune with more examples at both training and test time. It’s an open question how far they can get with scaling up this approach. And, as I mentioned when discussing to Greenblatt’s method, it’s also an open question whether MindAI’s approach, if successful on the ARC prize competition as result of enormous amounts of search, will be relevant for abstraction and analogical thinking in the real world.
The ARC Prize and the Perils of Goodhart’s Law
I’m genuinely excited about the ARC Prize and the visibility it is giving to the importance of abstraction and analogy in human and machine intelligence.
However, Chollet created ARC to be “a measure of intelligence“. As with any other AI benchmark that gets a lot of attention, we need to worry about Goodhart’s Law: “When a measure becomes a target, it ceases to be a good measure.” ARC now is a $500,000 target where everyone is aiming at the bullseye. The problem is that when people focus on a specific target (e.g., top score on the ARC private evaluation set), they sometimes lose sight of what the benchmark is actually trying to measure (e.g., capacities for few-shot abstraction based on core knowledge concepts), and the methods developed to hit the target might miss the original motivation altogether.
One thing that could mitigate this kind of “overfitting” to a target is to make the private evaluation set more dynamic: instead of evaluating methods on a fixed 100-task set, the tasks in the evaluation could be continually changed. Maybe this is what Chollet has in mind for the future; I certainly hope so! In the meantime, I’ll be keeping a close eye on this fascinating and quickly developing story in the AI landscape.
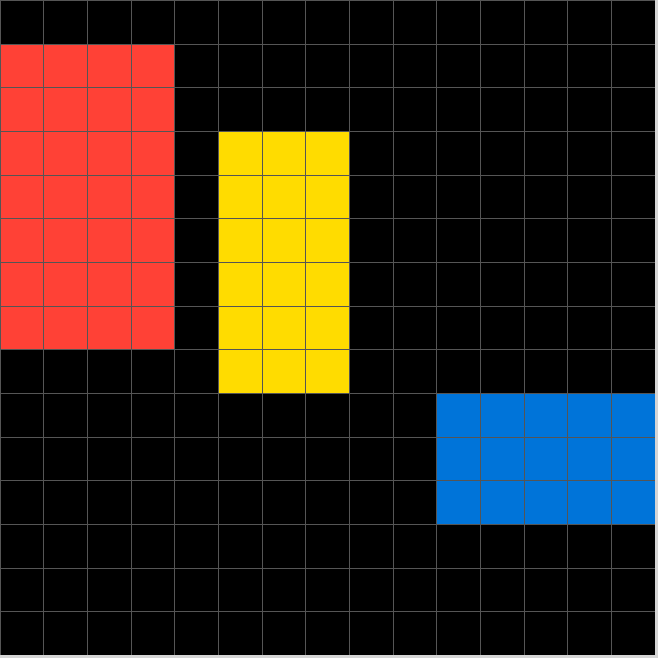
Answers to ARC example tasks from the beginning of this post:
Example 1 answer:
Example 2 answer:

Example 3 answer:

For me, the most important part is this: "when people focus on a specific target (e.g., top score on the ARC private evaluation set), they sometimes lose sight of what the benchmark is actually trying to measure (e.g., capacities for few-shot abstraction based on core knowledge concepts), and the methods developed to hit the target might miss the original motivation altogether."
The benchmark has "Abstract" in the title for a good reason. It is not supposed to be beaten through brute-force methods and sampling multiple answers, hoping one of them will work.
Pretty easy to avoid these pitfalls in my future evaluation projects.
1. Add $1million in prize money
2. Name it AGI
Hah. Nice piece!